Token 不够用,钱也不够烧:一个 AI 乐观主义者的自我怀疑
Apr 23, 2026, 10:00 AM
最近有一种很矛盾的感觉,想写下来。
Token 的消耗量在疯涨,但 AI 远没有普及。看看这张图:
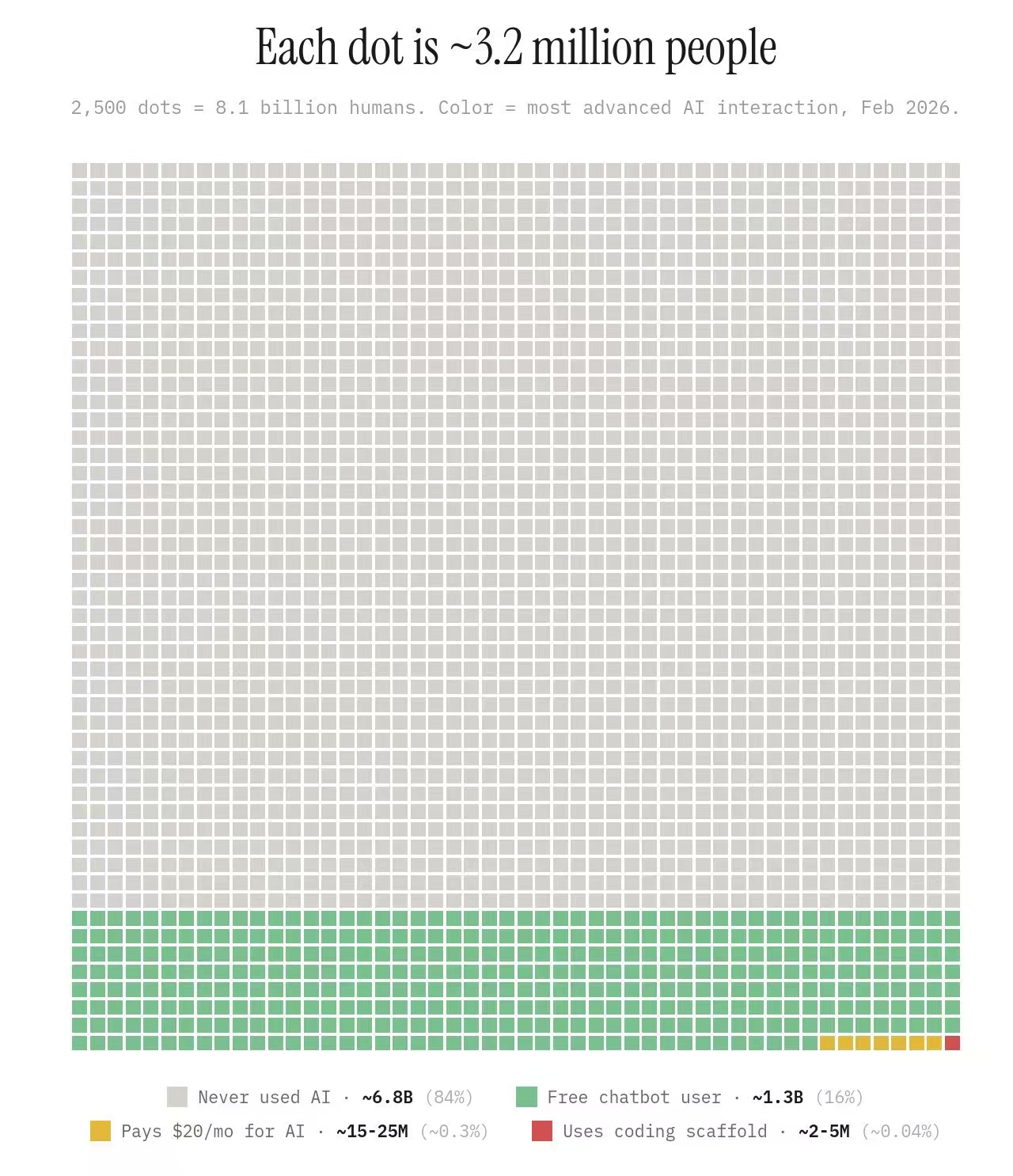
每个点代表 320 万人。灰色是从未用过 AI 的——84%,68 亿人。绿色是免费用户——16%。付费用户?0.3%。用 coding scaffold 的?0.04%,全球不到 500 万人。你我大概率在那个几乎看不见的红点里。
就这样,算力已经开始不够了。而且中美不够的方式还不一样——中国缺卡,美国缺电。一个被卡脖子,一个被物理定律卡脖子。需求还在山脚下,供给已经见顶了?
但我又觉得,现在的 token 消耗是极其浪费的。
大量的 token 花在了让 AI 去适应人类几十年积累下来的旧体系上。解析 PDF,读取 Word,处理 Excel,理解那些为打印机和人眼设计的格式。这就像让一个超级大脑通过传真机跟你沟通。
说句可能有争议的话:PDF、Word 这些东西,长期来看不应该存在。它们是打印机时代的遗产,对 AI 极其不友好。未来应该是 agent-friendly 的时代,底层是结构化数据,人看到的只是一层按需渲染的皮肤。(其实我自己的简历已经是这么管理的了——JSON 存数据,LaTeX 编译成 PDF,中间全程由 AI agent 维护,我只需要说一句"更新 CV"。)
Claude 对此的补充比我更精确:不是 agent-friendly,而是 agent-first, human-readable。因为 accountability 仍然需要人来承担——合同要人签、审计要人做。所以格式不会消失,但会从"信息的容器"变成"信息的渲染层"。我觉得这个说法对。
当整个体系变得更 AI-native,单位 token 的效率一定会大幅提升。但问题是——效率的提升从来不会降低总消耗。经济学上叫 Jevons Paradox:蒸汽机效率提高了,煤的消耗反而更多了。Token 变便宜了,大家只会用得更多。所以算力,可能永远不够。
到这里,逻辑上我应该得出一个乐观的结论:需求无限,前途光明,all in AI。
但我说服不了自己。
GPU 债务堆积如山,美国 GDP 增长里几乎全是 AI 基建,OpenAI 一轮融 1220 亿美元估值 8500 亿。每一家公司都在讲 AI 故事,每一个 VC 都在投 AI,每一个国家都在建数据中心。这画面太熟悉了——上一次看到类似场景的时候,是 1999 年。
要说这里面没有泡沫,我不信。
跟 Claude 聊这个矛盾的时候,它给了我一个框架,来自经济学家 Carlota Perez 的技术革命理论:每一次重大技术革命都会经历"安装期"和"部署期"。安装期,资本疯狂涌入,基础设施过度建设,泡沫膨胀。然后崩盘。然后,用那些"浪费的"基础设施,技术进入真正的普及期。
互联网就是这么过来的。1999 年铺的光纤电缆,泡沫破了,大部分公司死了,但电缆还在。Google、Amazon、Facebook 踩着那些光纤长大的。泡沫不是繁荣的对立面——泡沫是繁荣的安装费。
这个解释逻辑上很完美。今天的 GPU 集群、数据中心、电网扩建,就是这一轮的"海底光缆"。短期看是泡沫,长期看是必要的过度投资。因为如果所有人都理性,没人会在需求还没到的时候先把路修好。
但知道这个框架,并不能消除我的焦虑。因为你不知道自己处在 1997 还是 1999 还是 2003。身处其中的人,永远无法判断安装期什么时候结束、崩盘什么时候开始、部署期什么时候到来。
所以我的矛盾依然在:我相信 AI 会改变一切,我也相信这里面有巨大的泡沫。这两件事同时为真。而历史告诉我们,承认"我不知道时间表"可能是唯一诚实的立场。